A walkthrough of a simple EDA workflow using pandas and matplotlib.
Author
Jonathan Pearce
Published
February 15, 2026
Overview
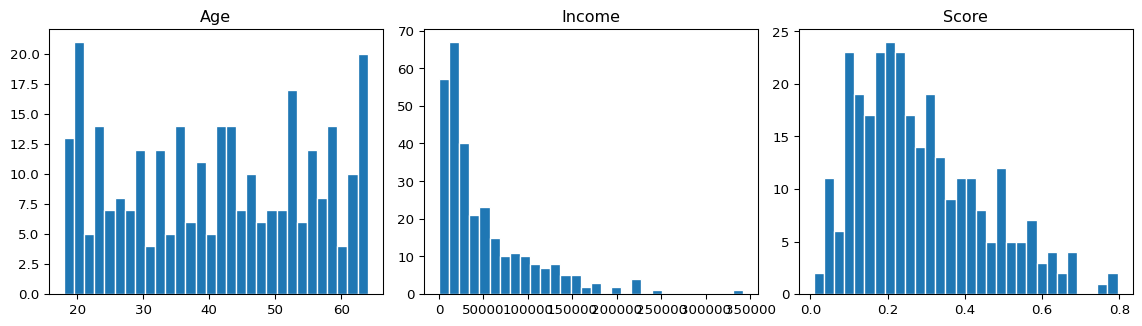
This example post demonstrates how a typical Exploratory Data Analysis (EDA) blog post looks on this site. It generates synthetic data so the post renders without external dependencies.
Generate Data
Code
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltnp.random.seed(123)n =300df = pd.DataFrame({"age": np.random.randint(18, 65, n),"income": np.random.exponential(50000, n).round(2),"score": np.random.beta(2, 5, n).round(4),})df.head()